
U. S. T . H . B
Institut de gťnie mťcanique

Introduction
![]()
![]()
![]()
![]()
![]() 0.4 - algorithmes gťnťtiques parallŤles et dynamique du population
0.4 - algorithmes gťnťtiques parallŤles et dynamique du population
Chapitre 1 (
Principe de fonctionnement)![]()
![]()
![]()
![]()
![]()
chapitre 2 (
codage binaire )![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
chapitre 3 (codage rťel)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
chapitre 4 (
exemple explicatif )![]()
chapitre 5 (
conclusion gťnťrale )![]()
![]()
INTRODUCTION
D
ťfinir ce quíest líintelligence est une question quíil serait peu sage de soulever ; une rťponse circonstanciťe relŤve de líutopie. Mais ŗ dťfaut de cerner avec prťcision les concepts qui sous-tendent líidťe que chacun de nous se fait de líintelligence, il est possible de rťflťchir aux diffťrentes formes que peut prendre líintelligence.La premiŤre qui nous vient ŗ líesprit, le plus naturellement du monde, est líintelligence humaine. La seconde, un peu moins immťdiate, est líintelligence collective, ou líintelligence sociale. Cíest une intelligence qui ne repose pas sur les facultťs díun seul individu comme le fait dans une certaine mesure líintelligence humaine-mais sur líinteraction díun grand nombre díindividus. Ce qui est remarquable, cíest quíaucun des individus de cette fragile construction, síil est pris sťparťment, ne saurait prťtendre ŗ une quelconque intelligence. Il ne nous viendrait pas ŗ líidťe de dire quíune fourmi ou une abeille est douťe de raison. Et pourtant, il est manifeste quíune fourmiliŤre ou une ruche constitue une entitť intelligente
La troisiŤme forme díintelligence, presque confidentielle mÍme si elle subsumme en quelque sorte les deux autres est celle de líťvolution. Pour arriver ŗ un homme capable de raisonner ŗ une ruche dont les membres peuvent communiquer et coopťrer, il fallu des millions d Ďannťes díťvolution. Or cette ťvolution níest pas aveugle, en ce sens quíelle a su utiliser le mťcanisme le plus efficace pour prťserver la vie : líadaptation. En effet, arriver ŗ trouver une solution ŗ un problŤme aussi complexe que celui de la survie dans un environnement en perpťtuelle mutation ne peut Ítre dŻ uniquement au hasard. Certes, ladite solution níest peut-Ítre pas la plus optimale, mais elle est certainement satisfaisante.
Cíest en cela que líťvolution des espŤces est en soi une forme díintelligence ; elle est peut
Ítre la moins apparente, mais elle est une indubitablement la premiŤre ŗ Ítre apparue, une sorte díintelligence originelle.
0.1- De líťvolution naturelle ŗ líťvolution artificielle
Il est donc tout ŗ fait naturel que des chercheurs díhorizons divers aient pensť ŗ síinspirer des mťcanismes qui font la force du processus díťvolution. Tout a commencť avec la thťorie de Darwin sur líorigine des espŤces, et son cťlŤbre principe du survival of the fittest, la survie des plus adaptťs [Darwin,1859]. Mais ce qui níťtait ŗ líorigine quíune thťorie biologique est devenue entre les mains de pionniers comme [Hollond,1962] ou [Bagley,1967] un formidable outil díoptimisation, mÍlant informatiques, mathťmatiques
Et biologique. [Holand,1975] pose les fondements thťoriques des algorithmes, passant du
Paradigme de líťvolution naturelle ŗ celui de líťvolution artificielle. Líidťe qui prťside ŗ ce
Changement de perspective est ŗ fois simple et ťlťgante : puisque líťvolution semble Ítre
un moyen efficace pour favoriser líťmergence de solutions adaptťes ŗ un environnement
complexe, pourquoi ne pas en simuler les processus pour trouver la solution globale ŗ un problŤme donnť? Pour rťsoudre le problŤme considťrť, il suffit alors de gťnťrer une population de solutions potentielles qui ťvolueront dans líordinateur síadapteront ŗ líenvironnement dťfini par le problŤme. Ces solutions sont reprťsentťes par líťquivalent digital díun chromosome. Et cíest sur ce ADN digital que sont appliquťs des opťrateurs
qui síinspirent tout naturellement des opťrateurs classiques de la biologie, que ce soit le croisement, la mutation, ou la sťlection.
0.2 - Líťvolution artificielle, une mťthode díoptimisation efficace
Une nouvelle ťtape est franchie lorsque les travaux de [Goldberg, 1989] donnent aux algorithmes gťnťtiques leurs lettres de noblesse en tant que mťthode díoptimisation viable, efficace, et non spťcifique. Ils traduisent plus prťcisťment les prťoccupations díun ingťnieur
doublť díun thťoricien, tout aussi intťressť par des considťrations purement thťoriques que par les aspects applicatifs. Les quelques applications utilisant les algorithmes gťnťtiques suscitťs jusque lŗ voient alors leurs nombres augmenter de maniŤre impressio. On retrouve les algogťnťtiques, ou plutŰt les algoriťvolutionnaires au sens large, dans un nombre díapplications considťrable [Mitchell, 1997]. Les domaines díapplications sont aussi variťs que la gestion de gazoducs [Goldberg, 1987], le contrŰle actif de vibration [Curtis, 19991], líoptimisation de la combustion dans des fourneaux [Fogarty,1990] , ou la charge des rťacteurs nuclťaires [ Back,1997] .Les algorithmes gťnťtiques donnent chaque cas des rťsultats suffisamment intťressants pour que leur usage soit en train de se gťnťraliser ŗ pratiquement tous les domaines liťs a líoptimisation.
0.3 - Evolution, thťorie des jeux, et optimisation multi-objectifs
Líanalogie avec la biologie, ainsi que la richesse apportťe par les ťchanges interdis-
ciplinaires entre gťnťtique et informatique, sont indiscutablement les facteurs clťs de la rťussite des algorithmes ťvolutionaires. Mais ce schťma níest pas isolť, en ce sens que líinterdisciplinaritť se rťvŤle souvent payante. En effet, en amont des modťlisations issues de la biologie, nous avons ťgalement explorť les outils que propose la thťorie des jeux [von neummann et morgenstern,1944]. Cet intťrÍt est nť du fait que pour modťliser de maniŤre plus rťaliste certains des problŤmes que nous avons ťtť amenťs ŗ traiter, nous avons dŻ-nous
Rendre ŗ líťvidence : une optimisation dans le cadrťaliste díun contexte industriel ne peut faire abstraction de la dimension multi-critŤres des problŤmes. Le terme dí ingťnierie concurrente Ē a mÍme ťtť forgť assez rťcemment pour traduire líimportance considťrable que prend líoptimisation multi-critŤres. Or la thťorie des jeux propose justement un panel de formalisation permettant de modťliser les problŤmes multi-objectifs [Mckinsey, 1952]. Il existe dťjŗ des algorithmes gťnťtiques qui propose des mťcanismes permettant de traiter des problŤmes díoptimisations multi- objectifs, mais ils font presque excltaťcoopťratifs de pareto. Pour mieux tirer parti de líimmense richesse que recŤlent les fondements de la thťorie des jeux, nous avons construit des algorithmes ťvolutionnaires qui mÍlent outils gťnťtiques et fondement s thťoriques comme les ťquilibres compťtitifs de Nash ou les ťquilibres hiťrarchiques de stackelberg [Periaux, 1997].
0.4 -
Algorithmes Gťnťtiques ParallŤles et dynamique des populationsUne derniŤre source díinspiration, qui apporte elle aussi des ťlťments nouveaux aux algorithme gťnťtiques est la dynamique des populations. Les ťtudes menťes dans ce domaine permettent en effet de proposer une modťlisation des algorithmes ťvolutionnaires non plus comme une unique population de grande taille, mais plutŰt comme un ensemble de sous populations de taille plus petites. Ce qui mŤne ensuite ŗ líťlaboration díun paradigme prometteur, celui des algorithmes gťnťtiques parallŤles.
![]()
PRINCIPE DE FONCTIONNEMENT
Ce chapitre síattache ŗ prťsenter les principes fondamentaux qui rťgissent les algorithmes gťnťtiques. Sans entrer dans les dťtails, il síagit en fait díexpliquer díune intuitive la maniŤre dont líanalogie entre ťvolution artificielle et ťvolution naturelle síťtablit.
- ReprťsentationLes algorithmes ťvolutionnaires constituent une famille díalgorithmes qui síinspirent
Des lois de la gťnťtique et du principe de la sťlection naturelle. Le principe fondateur consiste ŗ considťrer tout problŤme díoptimisation ou de contrŰle comme un environnement
dans lequel ťvolue une population de solutions potentielles. Cette particularitť des algorithmes ťvolutionnaires leur permet díexplorer líespace de recherche de maniŤre beaucoup plus efficace, puisque cíest une recherche ŗ la fois multidimensionnelle et capable
de dťjouer les piŤges que constituent les minima locaux.
Chacune des solutions de la population est en effet reprťsentťe par une structure digital
(par exemple une chaÓne binaire ), qui est líanalogue exact díun chromosome .
líťvolution síeffectue en mimant les opťrateurs de croisement et de mutation, puis en appliquant une sťlection gr‚ce ŗ une version informatique du principe darwinien du survival of the fittest. Face ŗ un problŤme díoptimisation, la premiŤre ťtape nťcessite donc de formaliser un certain membre de solutions dans un langage appropriť et elles seront ensuite
Considťrťe comme des individus. Si líon ne choisit de considťrer que des chromosomes de taille fixe, il síagit de faire correspondre ŗ chaque individu une chaÓne de langueur :
n ( x
1 x2 x3 Ö xn ) qui le codera.Par analogie avec les ťquivalents gťnťtique, on appellera cette chaÓne le gťnotype de líindividu, mais on y rťfťra ťgalement par le terme de chromosome. Comme ces individus sont reprťsentťs par un unique chromosome, on parlera díhaploÔdie. Xalgorithmes ťvolutionnaires ! haploÔdie les chromosomes sont constituťs de gŤnes ou de caractŤres.
Les diffťrentes positions sur la chaÓne chromosomique sont les loci. Chaque gŤne peut prendre diffťrentes valeurs, les allŤles.
Chaque gťnotype code donc une solution potentielle. On peut par exemple coder dans une chaÓne les dimensions díune ťtagŤre. Mais líťtagŤre au sens physique du terme est dťsignťe
par le terme de phťnotype, qui correspond ŗ la rťalisation díun gťnotype. Les taxons x1 x2 ÖÖxn peuvent prendre leurs valeurs dans líalphabet A, qui correspond ŗ líensemble des allŤles. Les algorithmes gťnťtiques classiques utilisent souvent un simple alphabet binaire
( A=0,1). Mais eu ťgard ŗ la complexitť des problŤmes traitťs et aux prťcisions nťcessaires, díautres approches privilťgient des codages plus complexes, comme le codage rťel (A=IR)
[Janikow et michalewicz, 1991].
La structure de base díun algorithme gťnťtique est la suivante :
1.2 - Algorithme 1 (Description díun algorithme Gťnťtique simple)
Pour un problŤme de minimisation J, un algorithme gťnťtique simple de la maniŤre suivante :
(1)
Gťnťration alťatoire díune population de N individus ;(2)
Evaluation de la qualitť du phťnotype de chaque individu ;(3)
Sťlection díun couple de parents au moyen díune procťdure appropriťe ;(4)
Croisement des deux individus avec une probabilitť Pc pour gťnťrer deux enfants ;(5)
Mutation des deux enfants avec une probabilitť Pm ;(6)
Rťpťter les ťtapes 3, 4, et 5 jusquíŗ ce que la nouvelle population contienne N individusDans ce modŤle, un processus de sťlection retient les individus les mieux adaptťs et les
transmet ŗ un processus díexploration qui les utilisera pour crťer de nouveaux individus
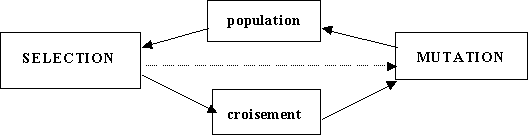
(Donc de nouvelles solutions potentielles au problŤme qui nous intťresse). La figure 1.1
Reprťsente le schťma de fonctionnement díun algorithme gťnťtique simple.
AprŤs le processus de sťlection intervient un processus de crťation qui síinspire ťgalement de la gťnťtique puisquíil fait intervenir les notions de reproduction, de croisement et de mutation. La reproduction consiste ŗ reproduire un individu tel quel dans la gťnťration suivante. Le croisement correspond ŗ la crťation de deux enfants en combinant les gŤnes de deux parents choisis par le processus de sťlection. Enfin la mutation revient ŗ introduire une modification alťatoire dans le gťnotype díun individu.
1.3 - Qualitť díune solution : la fonction de mťrite
Le processus de sťlection consiste ŗ choisir dans la population P, constituťe par líensemble des individus, ceux qui semblent les mieux adaptťs. Cette notion díadaptation est inspirťe du principe de la sťlection naturelle (le cťlŤbre survival of the fittest, qui a lui-mÍme survťcu ŗ son auteur). Pour construire un algorithme ťvolutionnaire, il est donc nťcessaire díimiter aussi bien que faire se peut ce concept de survie des plus adaptťs, qui est la clť de voŻte de líapproche Darwinienne. La solutionretenue par la plupardes chedans le domaine consiste ŗ associer ŗ chaque individu une fonction de mesurant la qualitť dudit individu, la fitness fuction ou la fonction de mťrite. Cette fonction de mťrite correspond ŗ líadťquation de la solution au problŤme considťrť. De cette maniŤre, il devient possible de comparer les diffťrents individus, avec toujours ŗ
 líesprit líidťe de favoriser líťmergence des meilleurs.
líesprit líidťe de favoriser líťmergence des meilleurs.
FIG. 1.1 Ė principe de fonctionnement díun AG
1.4 - fonction de mťrite implicite
Un des principaux problŤme des algorithmes gťnťtiques est justement de construire une fonction de mťrite qui soit pertinente. Líťlaboration díune telle fonction dťpend bien ťvidement du problŤme envisagť, et elle nťcessite souvent líexistence de connaissances sur le domaine ou la mise au point díheuristique complexe. On notera cependant que certaines ťcoles arrivent ŗ síaffranchir de la notion de fonction de stricto sensu, ou du
Moins parviennent díavoir ŗ la dťfinir de maniŤre explicite [Dessalles, 1996].
On peut ŗ titre díexemple les travaux effectuťs en vie artificielle [Langton,1989]
Líidťe díun environnement comme tierra par exemple consiste ŗ crťer des organismes digitaux pour lesquels le temps CPU des ordinateurs sur lesquels il est installť est de líťnergie alors que la mťmoire reprťsente les ressources [Ray, 1991,1996].
Ces organismes synthťtiques se livrent en fait une vťritable bataille pour survivre [Dewdney, 1984]. On pourra ťgalement se rapporter ŗ [Dawkins, 1976] pour ses travaux relatifs aux
Biographes. Un autre paradigme puisant directement son inspiration dans la biologie est celui des rťseaux neurones artificiels [Bergman, 1989], qui se dťcline ťgalement sous la forme des rťseaux neurones ťvolutionnaires [Yao et , 1998].
Une autre thťorie, celle des systŤmes immunitaires artificiels, níest pas sans rappeler les algorithmes ťvolutionnaires puisquíelle est ťgalement inspirťe du monde du v[Perelson, 1989, Forrest et perelson, 1991]. Et comme pour les programmes de vie artificielles, la dťfinition díune fonction de mťrite níest nťcessaire [Wilson, 1985].
On pourra ťgalement se reporter ŗ [varela, 1994] pour une ťtude de líapproche prospective.
- Taille de la populationLe choix de la taille de la population est un des paramŤtres les plus importants díun algorithme ťvolutinnaires [goldberg, 1986]. Et par-lŗ mÍme, cíest líun des problŤmes majeurs
De nombreuses ťtudes ont ťtť menťes pour essayer de cerner la taille optimale de la population, mais sans obtenir de rťsultats vraiment gťnťralisables [Alender, 1992, reeves,1993].Certaines approches proposent des tailles de population variables, qui ťvoluent au cours du temps [Arabas, 1994]. La principale originalitť de ce modŤle est díÍtre plus proche de la rťalitť. En lieu et place díune population de taille fixe oý la fonction de mťrite sert ŗ la sťlection, il propose plutŰt díindexer líespťrance de vie díun individu ŗ sa fonction de mťrite. Les meilleurs individus reÁoivent bien sŻr une espťrance de vie supťrieure ŗ celle des moins bonnes solution. Au fur et ŗ mesure que la population ťvolue, les individus vieillissent
Et finissent par mourir lorsquíils arrivent au terme de leur espťrance de vie. Dans ce modŤle,
La taille de la population varie donc de maniŤre dynamique en fonction de líespťrance de vie des individus que la composent.
On trouvera dans le chapitre II.1 une ťtude dťtaillťe de la mise en place de population de trŤs petites tailles. Cette manipulation a principalement pour but díaccťder la convergence de líalgorithme. Un des avantages supplťmentaires est quíelle permet ťgalement díimplťmenter une version efficace díun algorithme gťnťtique parallŤle.
![]()
Codage binaire
C
e chapitre est consacrť aux algorithmes gťnťtiques ŗ codage binaire, et donne quelque uns des fondements thťoriques sur lesquels ils síappuient. Le codage binaire est non seulement la maniŤre la plus simple, mais aussi la plus rťpondue, de reprťsenter un chromosome dans un contexte informatique. De plus, une analogie assez naturelle síťtablit entre les 0 et les 1 de laReprťsentation binaire et les bases qui codent líADN par exemple.
On trouve ťgalement une vue díensemble des diffťrents opťrateurs de sťlection.
Croisement et mutation, avec quelque unes des variations qui se sont dťveloppťes au cours du temps. Enfin, une section est consacrer ŗ une prťsentation sommaire des Evollutionary Strategies et de líEvolutionary Programming.
-ReprťsentationLa premiŤre ťtape de la mise en úuvre díun algorithme gťnťtique consiste ŗ construire une reprťsentation des solutions potentielles aux problŤmes. La reprťsentation la plus frťquente est la reprťsentation binaire, en particulier parce quíelle se prÍte bien aux recherches thťorique. Supposons que líon ait ŗ rťsoudre un problŤme díoptimisation oý le paramŤtre est x
Et oý la fonction de mťrite (ťgalement appelťe fonction de coŻt en optimisation classique) est
j =f(x).
On commence par coder le paramŤtre x sous forme díune chaÓne binaire de longueur n dťpend
Du domaine de variation de x et du nombre dťcimal dont on a besoin.
Dťfinition 1
Soit d le nombre de dťcimales dťsirťes (la prťcision).
Soit xmax et xmin les bornes supťrieure et infťrieure de líintervalle de variation pour x
Soit n la taille minimale de la chaÓne binaire.
n est alors le plus petit entier tel que :
![]()
ainsi, pour x Є [-1.28,1.28], si líon veut une prťcision de 2 dťcimales, il faudra prendre n=8
pour le codage. En effet, comme :
![]()
On en dťduit que n=8 est le plus entier qui satisfasse la relation.
Quand n =8 et x Є [-1.28,1.28], la chaÓne binaire 00000000 correspondra alors ŗ la borne infťrieure xmin = -1.28 alors que 11111111 reprťsentera la borne supťrieure xmax = 1.28.
Les valeurs intermťdiaires sont linťairement rťparties entre les deux borne. de ce fait, on peut associer une valeur de x ŗ níimporte quelle chaÓne de longueur n = 8, gr‚ce ŗ la formule suivante :
![]()
La reprťsentation binaire prťsentťe ici est la plus simple, et a donnť lieu ŗ de multiples variantes. A titre díexemple, [Goldberg, 1991] est le premier parlť de messy genetic
Algorithms, pour lesquels le codage se fait par une sťquence binaire de taille variable et non plus fixťe arbitrairement. Plusieurs travaux ont ťgalement ťtť amenťs dans le but díexploiter plus avant les complexitťs de la vťritable structure chromosomique.
En marge des reprťsentations haploÔdes, on trouve quelques travaux qui prŰnent une structure diploÔde. On se reportera ŗ [Greene, 1994, 1996] pour les problŤmes díoptimisation stationnaires, et [Goldberg et smith, 1987, wong, 1995] pour la version non-stationnaire. La diploÔdie consiste ŗ tenir compte du fait que pour la plupart des espŤces, les chromosomes vont par pairies. Les allŤles sont donc appariťs deux ŗ deux, et un mťcanisme intervient. Si le gŤne dominant est couplť ŗ un gŤne rťcessif, seul le gŤne dominant sera exprimť dans le phťnotype final. Pour quíun gŤne rťcessif puisse Ítre exprimť, il doit nťcessairement Ítre couplť un gŤne ťgalement rťcessif. [Levenick, 1991] tente ťgalement de se rapprocher encore plus du modŤle biologique en insťrant des introns dans son codage.
Les gŤnes expression messy genetic algorithms (GEMGA) proposťs par [Kargupta, 1995,1997]
Vont encore plus loin dans líanalogie avec les mťcanismes du vivant. Ils síappuient en effet sur líexpression gťnťtique qui est nom donnť au processus de transcription des sťquences díADN vers les protťines.
La sťlection est un opťrateur clť sur lequel repose en partie la qualitť díun algorithme ťvolutionnaire. Líune des principales caractťristiques de tout opťrateur de sťlection est la pression sťlective exercťe sur la population. Cíest un paramŤtre díun maniement dťlicat, car opter pour une pression sťlective trop forte revient ŗ ťcraser dans líúuf toute forme de diversitť, pour ne garder que le groupuscule díindividu qui le haut du pať. Mais si líon verse dans líautre extrÍme, ŗ savoir une pression sťlective trop faible, líalgorithme tend ŗ rapprocher díune simple recherche alťatoire.
On pourra trouver dans [Dejong, 1975] un travail de pionnier sur líťlaboration et líťvaluation des diffťrents protocoles de sťlection. Nous allons prťsenter dans la suite de cette section quelques-unes des mťthodes les plus courantes. Une ťtude plus approfondie des aspects thťoriques, ainsi que certaines variantes plus complexes pourront Ítre trouvťes dans
[Baker, 1985,1987].
Cíest líancÍtre de toutes les mťthodes de sťlection, et elle tire son nom de sa ressemblance avec la roulette ou la loterie. Elle consiste ŗ affecter ŗ chaque individu une probabilitť díÍtre sťlectionnť proportionnelle ŗ sa fonction de mťrite. Pour un problŤme de maximisation, on
ConsidŤre une population de taille N.
Soit : pour i = 1,2,3ÖÖ. N fi la fonction díadaptation de líindividu i.
On pose : ![]() La Somme des valeurs des fonctions díadaptation de líensemble des individus de la population. La probabilitť Pi quíŗ alors
La Somme des valeurs des fonctions díadaptation de líensemble des individus de la population. La probabilitť Pi quíŗ alors
Líindividu I díÍtre sťlectionnť est : Pi = fi/F
Il est bien entendu que le modŤle le plus simple se fait avec remise, et quíun individu peut Ítre sťlectionnť un nombre ťlevť de fois. De cette maniŤre, les meilleurs individus sont susceptibles de jouer un rŰle dťterminant dans les gťnťrations suivantes. Une certaine diversitť est cependant maintenue, car mÍme les individus les moins performants conservent une chance díÍtre choisis. En effet, ∀i 1≤ i ≤ N, on a Pi>0, ce qui revient ŗ dire que mÍme líindividu le moins adaptť au problŤme considťrť (ou en díautres termes ŗ líenvironnement) a une probabilitť non nulle díÍtre choisis. Selon la terminologie proposťe par [ba,1], on dira de cette mťthode quíelle est preservative. Cela peut apparaÓtre comme une propriťtť annexe, mais dťs lors quíon considŤre des environnements qui ťvoluent avec le temps, il est crucial de garder en rťserve des individus apparemment ďinadaptťsĒ car leurs atypisme en fera de prťcieuses sourde matťriel gťnťtique en cas de modification brusque du problŤme. Cíest la une des forces des algorithmes ťvolutionnaires
La biodiversitť, ou du moins son analogue digital. Et mÍme si les conditions du problŤme ne changent pas, une population uniformťment homogŤne concentrťe au niveau díun optimum local ne peut en sortir que gr‚ce ŗ ces individus atypiques.
La sťlection stochastique avec reste síinspire trŤs fortement de la sťlection par roulette, sauf quíelle y ajoute un lťger aspect dťterministe. On commence par dťterminer la probabilitť Pi = fi/F quía chaque individu díÍtre sťlectionnť. Soit N la taille de la population. On pose alors Mi = N. Pi, oý Mi correspond au nombre moyen de copies quíun individu peut espťrer recevoir par une sťlection de type roulette. On dťfinit ensuite :
n
i =E(Mi) oý E dťsigne la partie entiŤrer
i = Mi-E(Mi) les ri sont les restesle caractŤre dťterministe de la sťlection stochastique avec reste intervient alors, car on affecte automatiquement ŗ chaque individu ni copies dans la gťnťration suivante.
Comme : ![]()
Il reste en gťnťrale un nombre ![]() de copies ŗ affecter pour complťter la
de copies ŗ affecter pour complťter la
Population de la gťnťration suivante. Pour attribuer ces copies restantes, le processus
Utilisť est une roulette classique, qui síappuie non pas sur les valeurs Pi mais sur les
Restes ri considťrons une population de taille N=4 constituťe de 4 solutions S1,
S2, S3 et S4, pour un problŤme de maximisation.
f=10 P1=10/25=0.4 M1=4.0.4=1.6 n1=E(M1)
f=7 P2=7/25=0.28 M2=4.0.28=1.12 n2=E(M2)
f=5 P3=5/25=0.2 M3=4.0.1=0.8 n3=E(M3)
f=3 P4=3/25=0.12 M4=4.0.12=0.48 n4=E(M4)
![]()
On affecte donc une copie ŗ S1 et une copie ŗ S2, mais il reste deux copies ŗ dťterminer pour complťter la population.
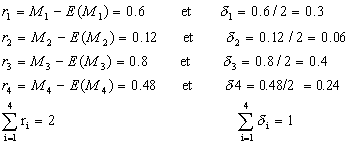
On relance alors une sťlection par roulette proportionnelle aux δi. On notera que la solution S3 est dťsormais la plus avantagťe.
Il existe plusieurs versions de cette sťlection, qui se diffťrencient principalement par le fait quíelles se font avec ou sans remise.
Toute une famille de mťthodes utilisent une sťlection qui níest pas directement proportionnelle ŗ la valeur de la fonction de mťrite, mais dťpend plutŰt du rang de líindividu
Dans la population. Le classement par rang, ou ranking, a principalement pour but díťviter que les individus avec des solutions de mťrite trŤs ťlevťes ne perturbent le processus stochastique en obtenant un nombre de copies trop important [Whitly, 1989].
Une sťlection par tournoi consiste, chaque fois que líon veut choisir un individu, ŗ sťlectionner un sous-ensemble de la population et ŗ ne conserver que le meilleur ťlťment du sous-ensemble. Si T est la taille tu tournoi, on sťlectionne alťatoirement T individus dans la population et on les fait entrer en compťtition : seul le vainqueur (donc celui qui a la meilleure fonction de mťrite) est retenu. Le processus est rťitťrť N fois, oý N est la taille de la population. Cette mťthode est caractťrisťe par une pression sťlective en gťnťral plus fortť que les mťthodes proportionnelles (pour quíun individu peu performant puisse Ítre sťlectionnť, il faut que ses adversaires soient encore moins bons que lui). Elle donne des rťsultats particuliŤrement bons dans les cas oý le caractŤre un peu trop alťatoire de la roulette introduit un biais.
On peut trouver dans [Goldberg, 1990] une variante de Boltzmann díune sťlection par tournoi. Elle rappelle certains aspects du recuit simulť puisquíelle fait intervenir la tempťrature dans la dťtermination du vainqueur du tournoi.
Le modŤle ťlitiste consiste ŗ recopier automatiquement le meilleur individu de chaque gťnťration dans la suivante. En effet, le caractŤre alťatoire de la sťlection fait que rien ne garantit que la meilleure solution soit conservťe. Líťlitisme permet donc de síassurer que la meilleure solution de chaque gťnťration ne peut que síamťliorer avec le temps. Le modŤle ťlitiste níest pas une mťthode de sťlection en soi, mais plutŰt une variante quíon ajoute aux mťthodes dťjŗ citťes.
2.2.6-sťlection par troncature
il existe ťgalement des algorithmes ťvolutionnaires qui considŤrent que la sťlection ne doit
pas Ítre laissťe au hasard. Ainsi, les breeding genetic algorithms, dťveloppťs par [schlierkam-pvoosen, 1993] síinspirent des mťthodes de sťlection utilisťes par les ťleveurs. Líune des plus classique ťtant la sťlection par troncature (truncation selection) oý on choisit de maniŤre dťterministe les T% meilleurs individus díune gťnťration pour gťnťrer la suivante. Cela revient en quelque sorte ŗ gťnťraliser le modŤle ťlitiste ŗ tout le processus de sťlection.
Le croisement est le premier opťrateur qui intervient au niveau de processus de crťation. Il vital, en ce sens que cíest gr‚ce que síeffectuent les ťchanges díinformation au sein de la population. Chaque fois quíun individu est retenu par le processus de sťlection, on dťtermine alťatoirement síil doit participer ŗ un croisement (avec une probabilitť Pc) ou Ítre transmis directement ŗ líopťrateur de mutation. Dans le second cas, on parle de reproduction, car líindividu est reproduit tel quel dans la gťnťration suivante.
Soit J un individu choisi par líopťrateur de sťlection. Soit Rj un nombre alťatoire,
0 ≤ Rj ≤ 1. On a:
Si Rj ≤Pc alors appliquer líopťrateur de croisement sur j
Si Rj>Pc alors appliquer líopťrateur de reproduction sur j
Le croisement est la maniŤre la plus rťpandue de crťer de nouveaux individus : on choisit deux individus (les parents) et on les combine pour en gťnťrer deux autres (les enfants).
Cette combinaison utilise la notion de points de coupures qui correspond aux loici au niveau desquels síeffectuera líťchange de matťriel gťnťtique.
croisement simple ŗ un pointpoint de coupure
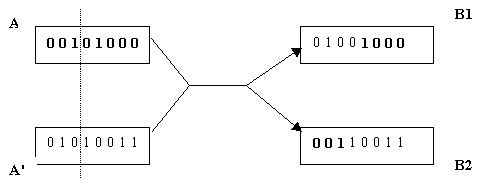
FIG. 2.1 opťrateur de croisement, un seul point de coupure
Le croisement ŗ un point est líopťrateur de croisement le psimple et le plus. Il consiste ŗ sťlectionner un point de coupure, puis ŗ subdiviser le gťnotype de chacun des parents en deux parties de part et díautre part de ce point. Les fragments obtenus sont alors ťchangťs pour crťer les gťnotypes des enfants. Ainsi, la figure 2.1 ťsente le cas oý le point de coupure tombe aprŤs le troisiŤme locus ; les parents A et Aí produisent alors les enfants B1 et B2.
points de coupure
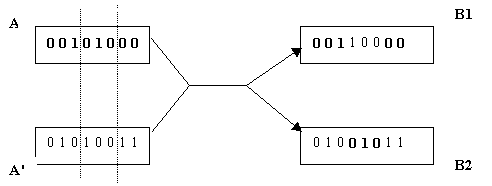
FIG : 2.2- opťrateur de croisement ŗ deux points de coupures
Le croisement multi-points est une gťnťralisation du croisement ŗ un point en ce sens quíau lieu de choisir un seul point de coupure, on en sťlectionne k. líintťrÍt díune telle approche apparaÓt rapidement, car il devient possible en un seul croisement díťchanger des building
blocks qui sont situťs au milieu du chromosome sans avoir ŗ procťder par ťtapes. Bien sur la contrepartie est que cíest une technique qui est plus destructrice par rapport ŗ ces mÍme building blocks, puisquíils peuvent se retrouver scindťs en plusieurs fragments sans intťrÍt. La figure 2.2 reprťsente un croisement ŗ deux points, dans le cas oý les points de coupure tomberaient aprŤs les troisiŤmes et cinquiŤme loci : les parents A et Aí produisent alors les enfants B1 et B2.
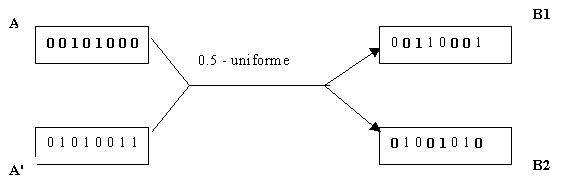
FIG.2.3- exemple de croisement 0.5-uniforme
Les fondements thťoriques du croisement uniforme ont ťtť posťs par[Syswerda, 1989].
Soient A et Aí les parents, et B1 et B2 les enfants. Pour chaque locus de B1, on dťtermine alťatoirement (avec une probabilitť P) si íallŤle est fourni par A ou par Aí. Le second enfant B2 se voit affecter líallŤle du parent qui nía pas ťtť retenu. Si B(k) dťnote la valeur de líallŤle au niveau du locus k pour le chromosome B, n la langueur du chromosome et r un nombre alťatoire, avec
![]() , on a :
, on a :
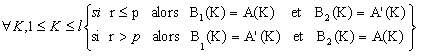
La fi2.3 montre un exemple de croisement 0.5-uniforme (chaque parent a une chance ťgale de transmettre son allŤle ŗ chacun des enfants pour tout les locis ). [Spears et Jong, 1991] proposent une analyse dťtaillťe des croisements p-uniformes.
Pour ce qui est des valeurs optimales du taux de croisement Pc, on pourra se rťfťrer ŗ [Eshelmant, 1989].
Il est gťnťralement admis que les valeurs de Pc comprises entre 0.8 et 0.95 donnent les rťsultats les plus satisfaisants dans la plus plupart des cas.
Certains problŤmes nťcessitent cependant la mise en ouvre de reprťsentations particuliŤres
Plus complexes, de type matriciel par exemple. Dans ce cas, les opťrateurs de croisement sont ťgalement plus complexes mais obťissent nťanmoins ŗ un principe commun, líťchange díinformation entre individus.
Il est ŗ noter que si les croisements prťsentťs ici mettent tous en jeux deux parents, ce níest pas toujours le cas. Il existe en effet des opťrateurs de croisement qui font intervenir trois parents, voire plus, les croisements multi-parents [ Eiben, 1994]. [Ackley,1987] a par exemple introduit un croisement par vote, que [Muhlenbein, 1989] a ensuite dťveloppť en
p-sexual voting recombination, ou recombinaison sexuťe par vote ŗ p parents.
La mutation est une modification alťatoire de la valeur díun gŤne qui se produit avec une probabilitť fixťe. Elle primordiale puisquíelle donne la garantie que tout point de líespace
de recherche peut Ítre atteint lors du processus díexploitation. Si Pm est la probabilitť de mutation, 0≤ r ≤ 1 un nombre tirť au hasard et que líon ait r < Pm pour le quatriŤme locus par exemple, alors :
allŤle a muter

FIG. 2.4 - opťrateur de mutation
Comme pour le taux de croisement, la recherche díun taux de mutation optimal a suscitť de nombreux travaux . On retiendra juste que les valeurs classiques de Pm oscillent entre 0.001 et 0.01.
2.5-Rťsultats thťoriques : le thťorŤme des schťmas
Une des raisons qui font des algorithmes gťnťtiques binaires une modťlisation fort apprťciťe est quíils se prÍtent bien ŗ certaines manipulations formelles. Un des exemples les plus communťment citťs dans la littťrature sur les algorithmes gťnťtiques est par exemple le thťorŤme de schťmas. Il síappuie sur la notion de schťmas utilisťe par HOLLAND,1975.
Dťfinition 2 (schťmas
)Un schťmas est une sťquence binaire enrichi de symbole, qui correspond ŗ une valeur indiffťrente, 0 ou 1. Ainsi pour le schťmas (0*00*0) reprťsente les 4 sťquences binaires suivantes :
(000000)
(010000)
(000010)
(010010)
Dťfinition 3 (ordre díun schťmas)
Líordre díun schťmas est le nombre de positions instanciťes. Si n est la langueur díun schťmas S et m le nombre de positions occupťes par des *, alors líordre 0(s) du schťmas
Est :
O(s) = n - m
Dťfinition 4 (longueur utile díun schťmas)
La longueur utile λ díun schťma est la distance entre la premiŤre et la derniŤre position instanciťes. Un schťmas S = (*10**00**) a pour longueur utile λ(s) = 7 Ė 2 = 5.
Dťfinition 5 (fonction de mťrite díun schťmas)
La fonction de mťrite díun schťmas est la moyenne des fonction de mťrite des chaÓnes binaires quíil reprťsente.
ThťorŤme 1 (thťorŤme de schťmas)
Les schťmas dont la longueur utile et líordre sont faibles, et dont la fonction de mťrite est meilleure que la fonction de mťrite moyenne de population reÁoivent un nombre de copie qui
Croit de maniŤre exponentielle au cours des gťnťrations díun algorithme gťnťtique.
Il est ťgalement possible díexprimer ce thťorŤme de maniŤre plus formelle pour un algorithme gťnťtique simple. Soit P(k) la population ŗ la gťnťration k, N le nombre díindividus de la population, et c(S,K) le nombre de copies du schťmas S dans la population P(k).
En admettant une sťlection par roulette, líapplication de líopťrateur de sťlection donne :
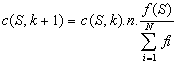
Oý F(S) est la fonction de mťrite du schťma S, alors que Fí est la fonction de mťrite moyenne de la population P(k).
Soit un opťrateur de croisement simple ŗ un seul point de coupure, et Pc la probabilitť de croisement uniforme rťpartie. Cet opťrateur dťtruit un schťma de longueur utile λ(S) avec
Une probabilitť Pd ťgale ŗ :
![]() Le schťma S survit donc ŗ líopťration de croisement avec une probabilitť:
Le schťma S survit donc ŗ líopťration de croisement avec une probabilitť:
Ps = 1 Ė PcPd.
AprŤs les phases de sťlection, on donc :
![]()
Soit Pm la probabilitť de mutation díun gŤne instanciť (donc diffťrent de *) de S, et o(S) líordre de S. le schťma S ne sera pas affectť par líopťrateur de mutation avec une probabilitť :
![]() Or Pm ťtant trŤs proche de 0, on a :
Or Pm ťtant trŤs proche de 0, on a :
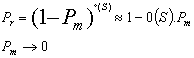 Ce qui signifie que S est modifiť par la mutation avec une probabilitť 0(S).Pm.
Ce qui signifie que S est modifiť par la mutation avec une probabilitť 0(S).Pm.
Líapplication successive des opťrateurs de sťlection, croisement et mutation donne en fin de compte la formulation qui ŗ líorigine du thťorŤme des schťmas:
![]() Ce qui revient ŗ dire que les schťmas ayant une fonction de mťrite supťrieure ŗ la moyenne,
Ce qui revient ŗ dire que les schťmas ayant une fonction de mťrite supťrieure ŗ la moyenne,
Une longueur utile et un ordre faible, reÁoivent un nombre de copies qui croit de maniŤre exponentielle.
Dťfinition 6 (building blocks)
Un algorithme gťnťtique construit des solutions optimales ou quasi-optimales en juxtaposant
Des schťmas courts, díordre faible, performants, quíon appelle les building blocks.
Les rťsultats thťoriques concernant les propriťtťs des algorithmes gťnťtiques sont tous fondťs sur une tentative de modťlisation formelle. La plus classique est sans doute une modťlisation par chaÓne de MARCOV, qui fournit un cadre mathťmatique adaptť aux algorithmes gťnťtiques.
[Cerf,1994] en particulier propose une formalisation poussťe des algorithmes gťnťtique síappuyant sur un modŤle MAKOVIEN. Il fait de plus appel ŗ des outils mathťmatiques trŤs ťlaborťs comme la thťorie de FREIDLIN-WENTZELL. Cette thťorie vise ŗ formaliser les petites perturbation alťatoires de systŤme dynamiques.
En combinant ces deux modŤle, CERF considŤre les algorithmes gťnťtiques comme une perturbation alťatoire díun mťcanisme de sťlection trŤrudimenta[Cerf, 19]. Il analyse
La maniŤre dont líintersection asymptotique entre les mutations et la force de sťlection entraÓne la convergence de líalgorithme vers les maxima globaux de la fonction díadaptation.
Il montre en particulier que lorsque la taille de la population est plus grande quíune certaine valeur critique, fortement dťpendante du problŤme, líinteraction assure la convergence de líalgorithme (en un temps ťventuellement fini) ces rťsultats comptent parmi les premiers rťsultats mathťmatiques se rapportant ŗ la convergence des algorithmes gťnťtiques.
CHAPITRE 3
Codage rťel
C
e chapitre est dťdiť aux algorithmes ťvolutionnaires ŗ codage rťel, et síattache ŗ souligner leur spťcificitť, leurs avantages et leurs inconvťnients. En effet, le codage binaire est bien adaptť ŗ certaines domaines, principalement parce quíil facilite la mise au point rťsultats thťoriques. Mais la puissances algorithmes gťnťtiques ne dťpend pas du codage binaire [Goldberg, 1990a].[Deb et Goldberg, 1989b] montrent en particulier que líune des caractťristiques qui fait la force des algorithmes gťnťtiques, ŗ savoir le parallťlisme implicite (voir [Dessalles, 1996]), níest absolument pas dťpendant de la reprťsentation binaire. Il existe de nombreux problŤmes oý un codage rťel est plus appropriť et donne de meilleurs rťsultats [Michalewicz, 1991].On trouvera ťgalement une prťsentation sommaire de deux approches qui ont choisi le codage rťel dťs le dťbut, les stratťgies díEvolution et Programmation Evolutionnaire.
La reprťsentation des solutions dans le cadre díun algorithme gťnťtique níest pas nťcessaire rťduite ŗ un alphabet de faible cardinalitť, comme líalphabet (A=0.1)
Prťsentť dans le chapitre prťcťdent. Il existe en effet toute une ťcole pour laquelle la reprťsentation la plus efficace est celle qui síappuie sur des nombres rťels, avec (A=IR)
Cette diffťrence de position a parfois pris des aires de querelle de clocher, opposant les puristes la thťorie, surs la faible cardinalitť ťtait la solution, et les partisans du codage rťel, qui pouvait montrer preuves ŗ líappui que les rťsultats ťtaient meilleurs pour de nombreuses applications rťelles. [Gldberg, 1990] propose une explication ŗ ce paradoxe apparent en síappuyant sur la notion díalphabet virtuel : il postule que quelle que soit la taille
De la líalphabet de dťpart, líespace de recherche est rapidement ramenť ŗ un sous-espace qui
Peut, lui, Ítre reprťsentť par un alphabet de faible cardinalitť. On pourra noter que le parti pris díun codage rťel a ťtť adoptť dŤs le dťbut par líťcole allemande des Evolution Strategies
[Rechenberg, 1973]. [Michalewicz, 1992] propose une ťtude dťtaillťe des algorithmes gťnťtiques avec codage rťel, soulignant en particulier leur robustesse dans le cas díapplications considťrťes comme difficiles pour des algorithmes gťnťtiques binaires.
líopťrateur de croisement pour le codage rťel est trŤs proche de celui dťcrit pour le codage binaire dans la section 2.3. soient A et Aí les parents qui ont ťtť choisis par le processus de
sťlection. Ils gťnŤrent deux enfants B1 et B2. Si on considŤre par exemple que cíest un croisement avec deux points de coupures, et que ces points de coupure tombent respectivement aprŤs le troisiŤme et le cinquiŤme loci on a :
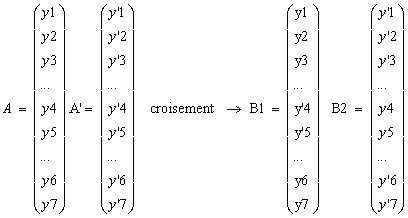
Bien ťvidement, les Y'I son ici tous des rťels, non plus des chaÓnes binaires codant des rťels.
Le croisement parait d'Ítre le mÍme que dans le cas du codage binaire, mai il existe de fait une diffťrence fondamentale : dans le cas rťel, le point de coupure tombe nťcessairement
Entre deux variables alors que la maniŤre dont sont codťes les variables en binaire fait que le point de coupure peut tomber ŗ l'intťrieure d'une variable. Pour le codage rťel, le croisement s'apparente donc plus ŗ une simple permutation des valeurs de variables existant dťjŗ.
Il n'y a donc jamais de crťation de valeurs nouvelles. De ce fait, l'espace de recherche est limitť aux
![]() combinaisons possibles des allŤles des parents.
combinaisons possibles des allŤles des parents.
Le codage rťel permet cependant de dťvelopper naturellement toute une sťrie de nouveaux types de croisement, principalement ŗ base de combinaison linťaire des deux vecteurs considťrťs. On peut trouver dans [Davis, 1993] une ťtude du croisement arithmťtique. Si A et A' sont les parents retenus par le processus de sťlection et B1 et B2 les deux enfants qu'ils gťnŤrent, alors le croisement arithmťtique est dťfini par :
B1= α . A+ (1-α). A'
B2= α .A'+ (1-α).A avec ![]()
Pour un algorithme gťnťtique binaire, l'exploration se fait principalement gr‚ce aux croisements, par le biais des ťchanges de building blocks. De ce fait, la mutation est souvent considťrťe comme un processus secondaire dans la plus part des cas. On a vu que l'opťrateur de croisement pouvait crťer de nouvelles pour les variables. C'est cette raison qui donne ŗ la mutation une importance prťpondťrante en codage rťel, car c'est elle qui assurera une partie importante du processus d'exploration.
Si les croisements sont assez similaires dans le des algorithmes gťnťtiques binaires et des algorithmes gťnťtiques rťels. La mutation est en revanche complŤtement diffťrente. Il ne suffit plus d'inverser un bit. Un certain nombre d'opťrateurs de mutation existent, et nous avons utilisť la mutation non- uniforme.
Si un gŤne yi doit subir une mutation, alors la nouvelle valeur yi' de la variable sera alťatoirement gťnťrťe dans l'intervalle [Mmin, Mmax], oý Mmax et Mmin sont les bornes supťrieures et infťrieures de la variable yi :
Yi'= yi+Δ(t, Maxi-yi) si θ=0
Y'i= yi-Δ(t, yi-Mini) si θ=1
t, correspond au nombre de gťnťrations ťcoulťes
θ, est un boolťen alťatoire
La fonction Δ(t, y) quant ŗ elle peut Ítre dťfini par :
Δ(t, y)= y.r.![]()
y, est la variable a muter
r, est un nombre alťatoire dans [0, 1]
t, correspond au nombre de gťnťrations ťcoulťes
T, est le nombre maximal de gťnťrations autorisťes
b, est un paramŤtre de raffinement (ou de non-uniforme).
La fonction Δ(t, y) est construite de maniŤre ŗ renvoyer une valeur dans l'intervalle [0,y]. de plus la probabilitť que Δ(t, y)tende vers 0 doit augmenter lorsque t augmente. Cette derniŤre contrainte permet ŗ l'opťrateur de mutation, aprŤs qu'un certain nombre de gťnťration se soit ťcoulť, d'affiner les solutions trouvťes lors de la phase d'exploitation.
On peut ťgalement prťfťrer une version plus complexe de Δ(t, y), comme par exemple :
Δ(t,y) = y.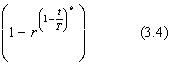
En utilisant la version la plus simple de Δ (eq. 3.3), l'ťquation 3.2 devient :
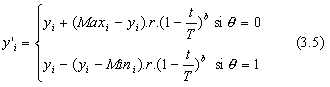
Durant les premiŤres gťnťrations, on a ![]() l'ťquation 3.5 donne alors :
l'ťquation 3.5 donne alors :
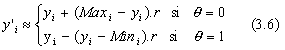
pour θ=0 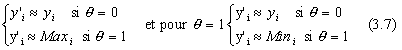
puisque r est alťatoirement gťnťrť dans [o, 1], il est claire que
![]() peut prendre toutes les valeurs comprises dans
peut prendre toutes les valeurs comprises dans ![]() . La mutation ainsi dťfinie permet donc ŗ l'algorithme d'aller en n'importe quel point de l'espace de recherche : c'est la phase d'exploration. En fait d'optimisation, on a
. La mutation ainsi dťfinie permet donc ŗ l'algorithme d'aller en n'importe quel point de l'espace de recherche : c'est la phase d'exploration. En fait d'optimisation, on a
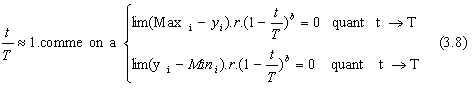
on pose
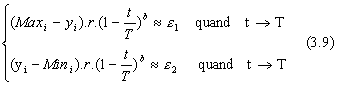
L'ťquation 3.5 se rťťcrit alors :
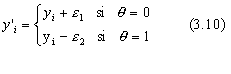
Quand t tend vers T, l'ampleur des mutations devient trŤs faible, puisque les nouvelles valeurs sont ťgales aux anciennes ŗ un
![]() prťs. Ce comportement est entiŤrement voulu, car il permet ŗ l'algorithme d'affiner les rťsultats obtenus lors de l'exploration : c'est la phase d'exploitation.
prťs. Ce comportement est entiŤrement voulu, car il permet ŗ l'algorithme d'affiner les rťsultats obtenus lors de l'exploration : c'est la phase d'exploitation.
La mutation non-uniforme constitue donc un compromis intťressant entre deux buts clairement concurrents, l'exploration de l'espace de recherche et l'exploitation des solutions obtenues.
Introdu
Hollanest souvent considťrť comme le pŤre fondateur des algorithmes ťvolutionnaires [holland,1975]. Mais il faut nťanmoins spťcifier qu'ŗ peu prťs ŗ la mÍme ťpoque est nťe en Allemagne une technique s'inspirant ťgalement des thťories de l'ťvolution, les evolutionsstrategies(ES)[Rechenberg,1973,Schwefel,1981].Ce qui fait l'intťrÍt des ES, c'est qu'elles ont ťtť conÁues avec ŗ l'idťe des utiliser comme optimiseurs, alors que Holland ne s'intťressait par particuliŤrement ŗ l'optimisation, mais plutŰt ŗ l'adaptation.
Stratťgie d'ťvolution (μ, k, λ, ρ)
Nous allons prťsenter dans cette section la version la plus gťnťrale d'ES [Back, 1997].
Dans les premiers temps des ES, trois diffťrentes formes coexistaient :
le symbole μ reprťsente le nombre de parents ŗ un moment donnť dans la population. Le symbole λ reprιsente quant ŗ lui le nombre d'enfants que gťnŤre les μ parents au cours d'une gťnťration. La dťfťrence entre ces versions concernent la maniŤre dont les parents de la gťnťration suivantes sont sťlectionnťs.
En effet, pour la stratťgie (μ+λ), les μ parents sont mťlangťs aux λ enfants, et on ne retiendra
Pour la gťnťration suivante que les μ individus les plus adaptťs de cet ensemble de cardinal (μ+λ), μ comme λ peuvent prendre des valeurs aussi petites que 1.
C'est le cas par exemple pour la stratťgie (μ+λ), mais c'ťtait encore plus vrai au tout dťbut des
ES, qui utilisaient une stratťgie (1+1).
En revanche, pour la stratťgie (μ,λ), oý λ>μ≥1, les μ individus de la nouvelle population sont
Nťcessairement sťlectionnťes parmi les λ enfants, mÍme s'ils sont moins bons que les parents.
Cette stratťgie implique que chaque individu ne peut avoir un enfant qu'une seule fois avant d'Ítre ťcartť.
C'est donc une diffťrence fondamentale avec la version (μ+λ) oý un individu peut vivre ťternellement si aucun enfant ne se montre meilleur. Pour ťviter que ce genre ne se produise, la version la plus complŤte (μ, k, λ) introduit un paramŤtre k≥1 qui correspond ŗ la durťe de vie d'un individu ( donc le nombre d'itťrations durant lesquelles il est conservť dans la population ).
La version (μ,λ) peut donc Ítre vue comme une instanciation de (μ, k, λ) avec k=1, alors que (μ+λ)correspond ŗ k = ∞.
La version la plus rťcente des ES un certain nombre de nouveaux paramŤtres, et en particulier:
la stratťgie d'ťvolution (μ, k, λ, ρ) peut alors Ítre dťfinie par le 19-uplet suivants:
![]()
![]()
avec:


un ES simple peut Ítre dťcrit par l'algorithme suivant:
Algorithme 2 (ES (μ,λ) et ES(μ+λ) )

3.4.2-Evolutionary Programming
Une autre approche appelťe Evolutionary programming a ťtť ťgalement dťveloppťe par
[Fogel, 1966].
A l'origine, les individus de la population ťtaient reprťsentťs comme des automates ŗ ťtats finis
Le but de cette technique ťtait de dťvelopper un individu capable de prťdire un changement dans son environnement. Plus tard, elle a ťtť ťtendue pour pouvoir traiter des problŤmes continus
Cette approche a certains points communs avec les ES comme avec les algorithmes gťnťtiques.
Les principales caractťristiques des EP est qu'il n'existe pas d'opťrateur de croisement. Comme pour les ES, c'est la mutation qui joue un rŰle primordial. Les EP utilisent en revanche une mťthode de sťlection probabiliste du type tournoi, alors que les ES utilisent plutŰt une sťlection par troncature. Un algorithme EP type peut se formuler de la maniŤre suivante:
Algorithme 3 (Evolutinary programming)

![]()
CHAPITRE 4
*************** Optimisation d'un multiplicateur ******************
RESUME
On considŤre líoptimisation díun multiplicateur par la programmation mathťmatique et les Algorithmes Gťnťtiques (AGs). Un problŤme statique est díabord rťsolu en utilisant SLP (Sequential Linear Programming), puis la maximisation de la premiŤre frťquence propre est obtenue par le placement de raidisseurs avec les AGs. Líefficacitť de ces derniers est testťe en comparant les rťsultats finaux díoptimisations sťquentielles SLP / AGs ŗ une optimisation globale par les AGs comprenant toutes les contraintes statiques et dynamiques du problŤme.
ABSTRACT
The optimization of a gearbox is considered here. It is performed using mathematical programming and Genetic Algorithms (GAs). A static problem is first solved using SLP (Sequential Linear Programming), then the first natural frequency is maximized locating stiffeners using GAs. The efficiency of the GAs is tested comparing the final results from some sequential optimizations SLP / GAs to a global optimization based on GAs incorporating the static and dynamic constraints of the problem.
I . INTRODUCTION
Une des difficultťs majeures rencontrťes dans le domaine de líoptimisation est la spťcificitť ou les limitations des algorithmes qui ne se rťvŤlent performants que pour des classes de problŤmes prťcises. Líexemple de líutilisation díalgorithmes basťs sur les gradients ( SLP, SQP, Directions RťalisablesÖ) (Haftka, 1992) pour des problŤmes dont les fonctions objectifs et contraintes doivent Ítres dťrivables en est líexemple le plus criant. Par extension ces mťthodes ne sont applicables quíaux problŤmes ŗ variables continues, occultant de ce fait tout le panel de problŤmes discrets, courants en mťcanique. Parmi les mťthodes ę dťdiťes Ľ aux problŤmes discrets, on trouve les algorithmes gťnťtiques (Goldberg,1973) dont la capacitť ŗ converger et leur indiffťrence aux irrťgularitťs des fonctions ont grandement contribuť ŗ leur succŤs. Des problŤmes de positionnement de raidisseurs (Fatemi
, 1998) ou díactionneurs (Furuya,1993), dedťtermination des sťquences d Ďempilement de plis pour les matťriaux composites (Le Riche, 1993) ont ťtť traitťs avec de telles mťthodes. Ce travail propose díťvaluer la capacitť des Algorithmes Gťnťtiques ŗ se rapprocher de la solution optimale díun problŤme mixte ŗ composantes continues et discrŤtes. En possession díoutils dťdiťs aux problŤmes continus et díautres aux problŤmes discrets, la solution díun problŤme mixte serait obtenue par la rťpťtition de sťquences díoptimisation du type (problŤme continu / problŤme discret) jusquíŗ convergence (figure 1)
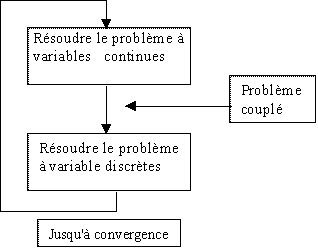
Figure 1 :
Convergence díun problŤme (continu / discret)
Cette ťtude a pour but principal de tirer des conclusions sur le comportement et la pertinence des Algorithmes Gťnťtiques utilisťs pour líoptimisation díun multiplicateur simple servant comme base de travail. Un problŤme statique en variables continues et un problŤme dynamique purement discret sont dťfinis. Le mťcanisme considťrť est tel que le couplage entre les deux problŤmes est faible. Ceci permet díobtenir une solution en trois ťtapes (continue / discrŤte / continue) ŗ laquelle nous pouvons confronter les Algorithmes Gťnťtiques pour la rťsolution du problŤme mixte dans sa globalitť.
II . PRESENTATION DU MODELE ET DU PROBLEME DíOPTIMISATION
II .1 Le modŤle
Le multiplicateur considťrť possŤde deux pignons ŗ denture hťlicoÔdale (figure 2). Líangle díhťlice de la denture est fixť ŗ 11.35į et líangle de pression ŗ 20į. Un couple díentrťe de 75 Nm est imposť sur la roue menante. De par la prťsence de la denture hťlicoÔdale, ce chargement a deux effets majeurs: - Un dťplacement axial relatif des deux roues. - Líapparition de contraintes au sein du carter. Afin de modťliser ce comportement, un modŤle ťlťments finis simplifiť a ťtť construit gr‚ce au code de calcul ANSYS (Swanson Analysis System Inc) (figure 3). Le modŤle, composť díťlťments poutres et coques, est tel que effets de la denture hťlicoÔdale prťcťdemment citťs sont pris en compte. Cela ťvite ainsi la construction díun modŤle volumique relativement gourmand en temps de calcul pour une procťdure díoptimisation.
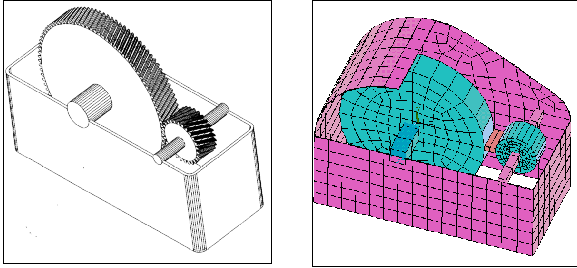
Figure 2 Figure 3
Multiplicateur ŗ denture hťlicoÔdale ModŤle Elťments finis
II . 2 ProblŤme díoptimisation
Nous proposons de minimiser la masse du multiplicateur sous les contraintes
suivantes :
- Le dťplacement axial relatif entre les deux pignons (
Δ z) est limitť ŗ 1 mm.- La contrainte de Von Mises sur le Carter est limitťe ŗ 150 MPa.
- La premiŤre frťquence propre du multipldoit Ítre supťrieure ŗ 105Hz.
Les variables utilisťes et leurs bornes sont :
5 mm
≤DiamŤtres des deux arbres ≤30 mm5 mm
≤ Une ťpaisseur pour les deux roues ≤ 40 mm2 mm
≤ Epaisseur du carter ≤ 5 mmOn appellera ProblŤme I, le problŤme continu ne comportant que les contraintes statiques
et ProblŤme II, le problŤme dynamique de nature discrŤte.
III .
SOLUTION PAR APPLICATION SEQUENTIELLE DE LA METHODE SLP ET LA METHODE AGIII . 1 Solution du ProblŤme I par SLP
Líutilisation de la mťthode par linťarisation sťquentielle fournit les rťsultats suivants
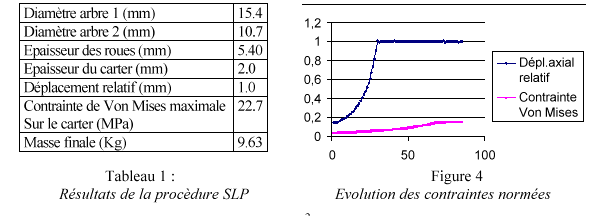
Le design obtenu rend la contrainte de dťplacement active alors que la contrainte de Von Mises níatteint que 19 % de la contrainte maximale autorisťe (Figure 4). Sur ce design obtenu on cherche ŗ obtenir des frťquences propres au delŗ de la plage díutilisation du multiplicateur comprise entre 0 et 105 Hz. La premiŤre frťquence propre du multiplicateur obtenue ťtant de 43.2 Hz. A cet effet, on vient placer des raidisseurs sur le carter gr‚ce aux Algorithmes Gťnťtiques.
III . 2 Solution du ProblŤme 2 par les Algorithmes Gťnťtiques
Soient cinq raidisseurs ŗ disposer le long du carter, et ce en 16 positions discrŤtes dťfinies par le maillage ťlťment finis. Leur nombre et leurs positions sont tels que la premiŤre frťquence propre est maximisťe pour une masse totale minimale, ce qui conditionne le nombre de raidisseurs utilisťs. Nous dťfinissons alors une fonction objective f de la faÁon suivante
![]()
 Les coefficients a et b sont choisis de telle sorte ŗ ce que la masse et la frťquence aient un poids comparable sur la fonction objectif.
Les coefficients a et b sont choisis de telle sorte ŗ ce que la masse et la frťquence aient un poids comparable sur la fonction objectif.
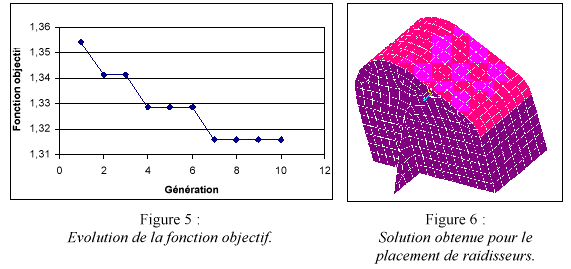
Pour ce problŤme les valeurs a=10 et b=40 ont ťtť choisies. Une dťmarche ťlitiste a ťtť utilisťe, cíest-ŗ-dire que le meilleur design díune gťnťration ( au sens de la fonction objectif dťfinie ci-dessus) est conservťe ŗ la gťnťration suivante. Une population de 15 individus avec un taux de mutation de 1% a ťtť employť. La solution obtenue correspond ŗ líemplacement díun raidisseur au niveau de líaxe du grand pignon (position A) (figures 5 et 6).Ce rťsultat peut Ítre interprťtť par le fait que le grand pignon reprťsente la plus grande masse dans le systŤme. Le premier mode correspond alors ŗ une translation axiale de ce pignon. La maximisation des frťquences propres est donc obtenue en localisant un raidisseur vis ŗ vis de líaxe du grand pignon. Ce raidisseur a pour effet de totalement modifier le problŤme statique, il faut donc relancer líoptimisation continue.
III . 3 Solution du ProblŤme I avec le(s) raidisseurs placť(s).
Líoptimisation par SLP du ProblŤme I avec le carter raidi fournit les rťsultats suivants
(Tableau 2).

Lŗ encore la contrainte de dťplacement devient active et la contrainte de Von Mises
obtenue reste faible.
III . 4 Doit-on continuer le processus ?
Líoptimisation continue effectuťe sur le multiplicateur dont le carter a ťtť raidi ne nťcessite pas de chercher ŗ repositionner des raidisseurs. En effet, les variables utilisťes sont telles que le problŤme ęmaximiser la 1er frťquence propre avec le nombre minimal de raidisseur Ľ trouve toujours sa solution dans le positionnement díun raidisseur au niveau de l Ďaxe du grand pignon. On est alors certain quíaprŤs trois itťrations, le processus ne permettra plus díamťlioration des problŤmes I et II. Ayant atteint par la procťdure sťquentielle (continue / discret) un ę optimum Ľ, il est alors intťressant de comparer le rťsultat final, ŗ ce que trouvent les algorithmes gťnťtiques pour le problŤme englobant la statique et la localisation des raidisseurs.
IV
. SOLUTION DU PROBLEME GLOBAL PAR LES ALGORITHMESGENETIQUES ET COMPARAISON
Le problŤme considťrť comporte dťsormais les contraintes statiques et le placement des raidisseurs. Nous recherchons le taux de discrťtisation ŗ donner aux variables afin díobtenir, pour des tailles de population raisonnables, une convergence satisfaisante. Discrťtisation en dixiŤmes de millimŤtre Les variables de dimensions sont díabord discrťtisťes en dixiŤme de millimŤtre ce qui se rapproche díun problŤme ŗ variables continues.
La taille de la population est fixťe ŗ 30. Les rťsultats obtenus avec les Algorithmes Gťnťtiques pour le taux de discrťtisation et la taille de population choisis montrent quíils ne rťussissent pas ŗ converger et ce sur une sťrie de dix essais. Aux vues de líampleur du domaine de recherche, ce rťsultat ťtait prťdictible. Discrťtisation en millimŤtres.
Le choix des coefficients a et b pour la pondťration des objectifs masse et frťquence est crucial pour líobtention díun optimum. En effet, les valeurs des masses et des frťquences et surtout leurs variations relatives ont des ordres de grandeur tout ŗ fait diffťrents. Pour cette raison il níexiste que certains couples (a,b) permettant de se rapprocher de líoptimum.
V. CONCLUSION
Un essai d'optimisation d'un problŤme mixte (continu / discret) sur un multiplicateur a ťtť effectuť. Le problŤme, d'abord rťsolu sťquensiellement par SLP puis les algorithmes gťnťtiques. Ces derniers se sont rťvťlťs efficaces pour des taux de discrťtisations des variables par pas d'un millimŤtre, la population comprenant 30 individus. l'ťtude montre aussi que les choix des coefficients de pondťration sont essentiels pour aboutir ŗ l'optimum.
![]()
chapitre 5
Conclusion
Dans ce mini-projet, nous avons essayť de mettre ŗ la portťe dugroupe productique, ĢĢles outils nťcessaires pour qu'ils puissent comprendre le principe de fonctionnement d'un
algorithme gťnťtique, et de les permettre voir de pris l'une des mťthodes efficace face ŗ un problŤme d'optimisation.
Pour cet intťrÍt, nous avons ťgalement, commencť par une introduction a fin d'expliquer, les trois formes d'intelligence humaine, et de faire les liens entre intelligence naturelle et intelligence artificielle, suivant l'historique de l'ťvolution de la pensť de l'homme.
Puis dans un premier chapitre nous attaquons le principe de fonctionnement et les fondamentaux qui rťgissent les algorithmes gťnťtiques, il s'agit en fait d'expliquer d'une maniŤre intuitive la maniŤre dont l'analogie entre ťvolution artificielle et ťvolution naturelle s'ťtablit.
Un deuxiŤme chapitre est consacrť aux AG ŗ codage binaire, et donne les fondements thťoriques sur lesquels ils s'appuient. On trouvera ťgalement une vue d'ensemble des diffťrents opťrateurs de sťlection, croisement, et mutation.
Le troisiŤme chapitre est dťdiť aux AG ŗ codage rťel et leurs avantages surtout dans les applications rťelles.
En fin le quatriŤme chapitre est dťdiť ŗ un exemple explicatif mais pas dťtaillť a fin de toucher les dimensions de l'application des algorithmes gťnťtiques dans la mťcanique et en particulier dans le domaine de la CFAO.
AN
: n.m Acide dťsoxyribonuclťique, Macromolťcule organique qui constitue le support universel de l'information hťrťditaire dans le monde vivant.AllŤle
: n.m Une des variantes possibles d'un gŤne *, s'exprimant dans le phťnotype * d'une maniŤre spťcifique.Chromosome
: n.m B‚tonnet colorable se trouvant dans le noyau cellulaire, et dont la composante principale -l'ADN- contient, sous une forme codťe l'information hťrťditaireCode gťnťtique
: correspondance naturelle ťtablie entre la sťquence des nuclťotides de l'ADN (ou celle l'ARN messager rťsultant de sa description) et la sťquence spťcdes aminoacides constituant les protŤinesGŤne
: n.m Les facteurs hťrťditaires -rťvťlťs par les lois de MENDEL-Gťnťtique ťvolutive des populations
: n.f s'occupe de la dynamique de la frťquence des gŤnes dans le cadre de population biologique.Gťnome
: n.m 1. La totalitť du matťriel hťrťditaire ; 2. Le patrimoine gťnťtique d'un organisme donnť. (Comparer avec gťnotype.)Gťnotype
: n.m La totalitť des informations hťrťditaires virtuelles contenus dans le gťnome* et dont une partie, constituťe par les caractŤres dominants, peut s'exprimer dans le phťnotype.HaploÔde
: adj. Se dit d'une cellule possťdant une garniture simple de n chromosomes dans son gťnome. C'est notamment le cas des cellules sexuelles.Mutation
: n.f Variation hťrťditaire accidentelle causťe par une modification du programme gťnťtique portť par une molťcule d'ADN. Selon l'ampleur des consťquences qu 'elle engendre.Phťnotype
: n.m La totalitť des caractŤres anatomiques, morphologiques, physiologiques ťthologiques caractťrisant un Ítre vivant donnť. Le phťnotype reprťsente la rťalisation du gťnotype en fonction de certaines conditions du milieu.Sťlection naturelle
: n.f Charles Darwin et alfred R.Wallace (1823-1913), indťpendamment l'un de l'autre, ont constatť le rŰle essentiel de la sťlection naturelle dans l'ťvolution des espŤces. Mais c'est le grand mťrite de darwin que d'avoir fait la sťlection naturelle le noyau durable de sa thťorie d'ťvolution.![]()
Rťfťrences
-1- Genetic Algorithm. Proeedings of the 7symposium on Multidisciplinary Optimisation. .
-2- Trusses by Genetic algorithms. ASME Winter Meeting.
-3- GOLDBERG, D.E .,1989, Genitic Algorithms in search, Optimisation and Machine
Learning, Addison Wesley
-4- Buckling laod Maximization by genetic algorithm. AIAA journal, Vol.31Nį5,pp951-957.
-5- Samy.Missoum @ema.fr
-6- Dictionnaire de biologie DENIS BUICAN larousse-bordas 1997